
浪潮信息发布创新开源大模型“源2.0-M32”
(全球TMT2024年5月30日讯)5月28日,浪潮信息发布了其最新的开源大模型“源2.0-M32”,该模型基于“源2.0”系列并引入了创新技术“基于注意力机制的门控网络”。通过构建一个包含32个专家的混合专家模型(MoE),显著提升了算力效率,模型运行时激活参数为37亿,使其在业界主流评测中与700亿参数的LLaMA3开源大模型相媲美。此外,该模型还采用了一种新颖的算法结构来优化MoE模型中专家之间的调度和协同处理数据,从而提高处理自然语言任务的精度和效率。
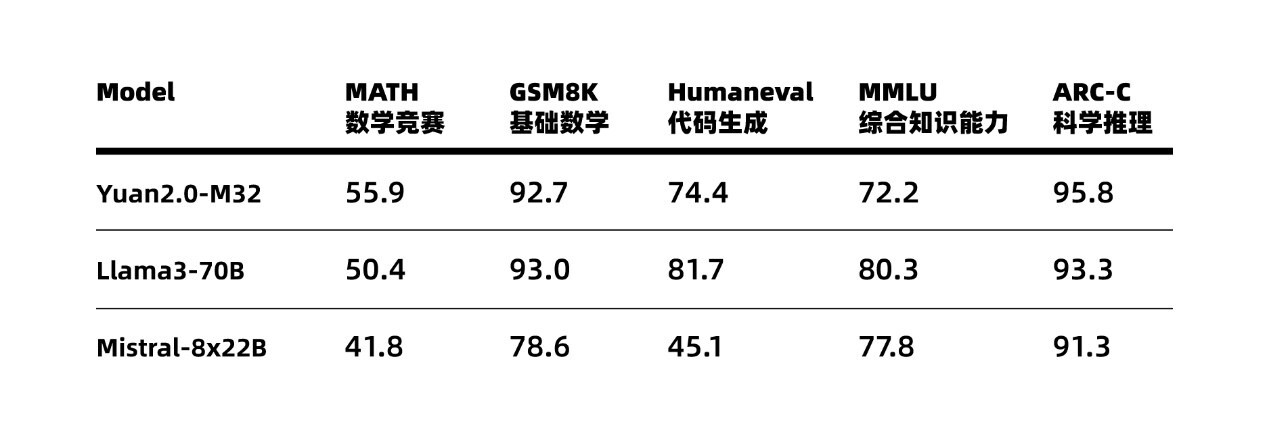
在数据方面,“源2.0-M32”进行了大规模训练,覆盖广泛类型的数据,包括代码、书籍、百科等,并特别扩展了代码数据比例至47.5%,从6类最流行的代码扩充至619类,并通过对代码中英文注释的翻译,将中文代码数据量增大至1800亿token。这些丰富和高质量的数据集使得该模型在代码生成、理解及推理等方面表现出色。同时,在算力层面,“源2.0-M32”采用流水线并行+数据并行策略,显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。“源2.0-M32”大幅提升了模型算力效率,在实现与业界领先开源大模型性能相当的同时,显著降低了在模型训练、微调和推理所需的算力开销。此外,“源2.0-M32”将持续采用全面开源策略,全系列模型参数和代码均可免费下载使用。




文章评论(0)